タンパク質ーペプチドドッキングシミュレーション
CONFLEX DOCKを用いてタンパク質ーペプチドドッキングシミュレーションを行い、指定したタンパク質とペプチドのドッキングポーズを見つけ出す方法を示します。ここでは、タンパク質として、Krev interaction trapped protein 1(PBD ID: 4hdq)を利用します。

【入力ファイルの作成】
Protein Data Bankよりダウンロードした4hdq.pdbを利用して、計算に必要な入力データを作成します。まず、A鎖の座標データ(596~3138行目)を抜き出して、別ファイル「4hdq_a.pdb」として保存します。
4hdq_a.pdbのテキストデータ
ATOM 1 N TYR A 419 10.722 15.896 36.775 1.00 65.31 N ATOM 2 CA TYR A 419 11.521 15.928 35.512 1.00 67.80 C ATOM 3 C TYR A 419 11.189 17.152 34.645 1.00 55.21 C ATOM 4 O TYR A 419 10.052 17.636 34.579 1.00 56.45 O ATOM 5 CB TYR A 419 11.346 14.624 34.690 1.00 75.21 C ... ... ATOM 2540 CG LEU A 729 31.167 9.539 -1.671 1.00 47.66 C ATOM 2541 CD1 LEU A 729 30.013 8.839 -0.939 1.00 44.71 C ATOM 2542 CD2 LEU A 729 30.768 10.892 -2.272 1.00 51.04 C TER 2543 LEU A 729
次に、ドッキングを行うペプチド配列を指定します。
ペプチド配列は、一次元配列を入力するか、あるいはpdbファイルを用意して読み込ませるかで設定します。4hdq.pdbには5残基のペプチドで構成されているC鎖(ARG-ARG-ASP-TYR-PHE、4440~4481行目)が含まれていますので、このデータを入力として使用するため、別ファイル(4hdq_peptide.pdb)として、4hdq_a.pdbと同じディレクトリーに保存します。
4hdq_a.pdbのテキストデータ
ATOM 3845 N ARG C1377 30.216 23.590 21.799 1.00 57.06 N ATOM 3846 CA ARG C1377 29.684 24.981 21.860 1.00 54.44 C ATOM 3847 C ARG C1377 29.284 25.473 20.457 1.00 59.72 C ATOM 3848 O ARG C1377 28.148 25.942 20.266 1.00 56.63 O ATOM 3849 CB ARG C1377 30.678 25.967 22.520 1.00 53.04 C ... ... ATOM 3883 CE1 PHE C1381 25.487 22.366 10.239 1.00 29.96 C ATOM 3884 CE2 PHE C1381 24.065 20.653 9.391 1.00 26.70 C ATOM 3885 CZ PHE C1381 24.252 21.944 9.721 1.00 28.89 C TER 3886 PHE C1381
【計算実行】
[Interfaceからの実行]
「4hdq_a.pdb」をCONFLEX Interfaceで開き、Calculationメニューから「Docking」を選択して、計算条件を設定します。
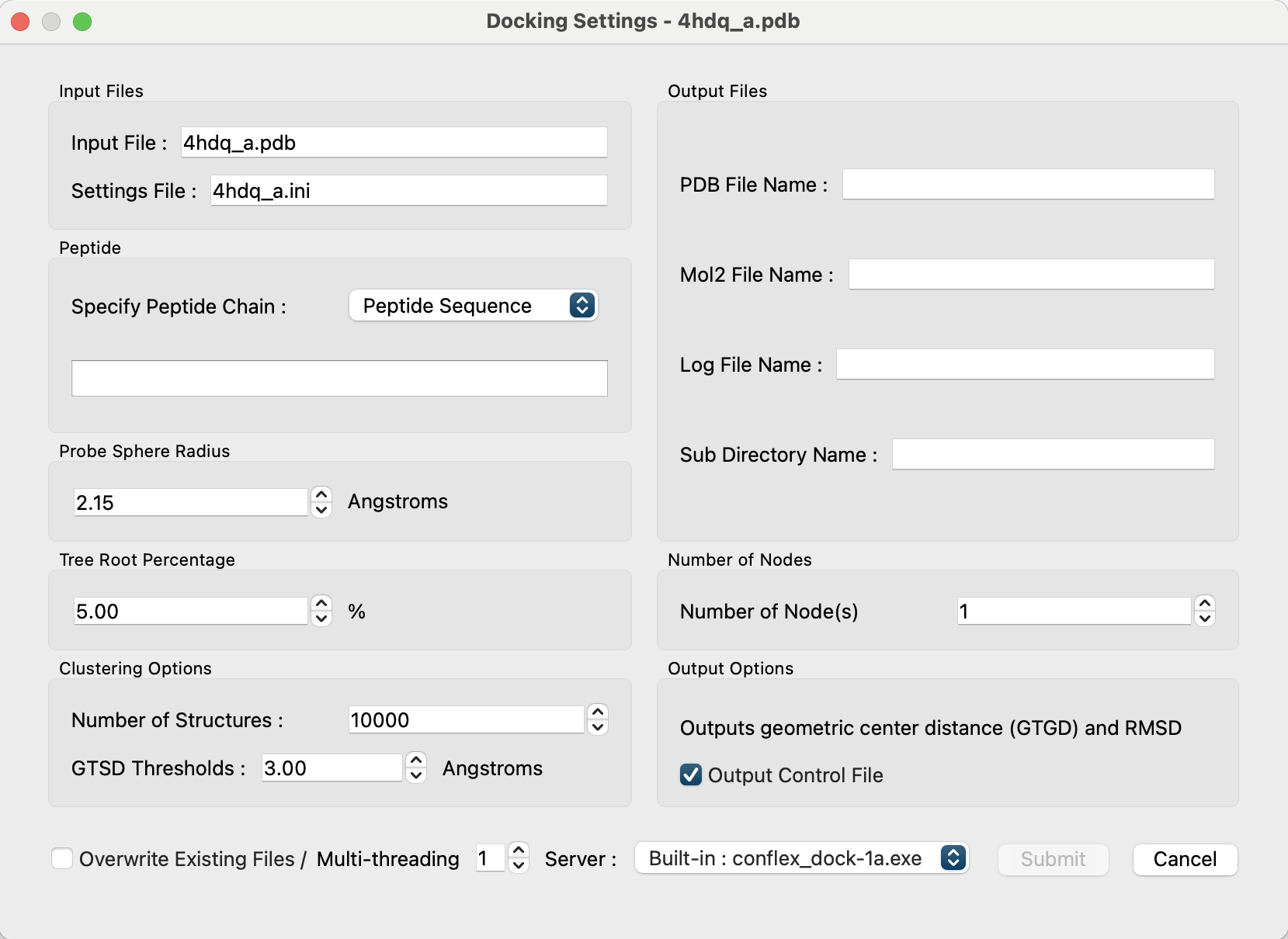
まず、「Peptide」欄の”Specify Peptide Chain :”を[Open File]とします。
すると、[Open FIle]ボタンがその下に現れます。

「Open File」をクリックして、作成した「4hdq_peptide.pdb」を指定します。
ファイルを読み込むと、ファイル名と残基の配列が表示され、「Output Files」欄の出力ファイル名とディレクトリー名に、入力PDBファイル名とペプチドのアミノ酸残基配列を足し合わせた名前(4hdq_a_ARG-ARG-ASP-TYR-PHE)が設定されます。
これらはそれぞれ個別に変更することも可能です。変更したい場合は、直接ボックス内を書き換えてください。
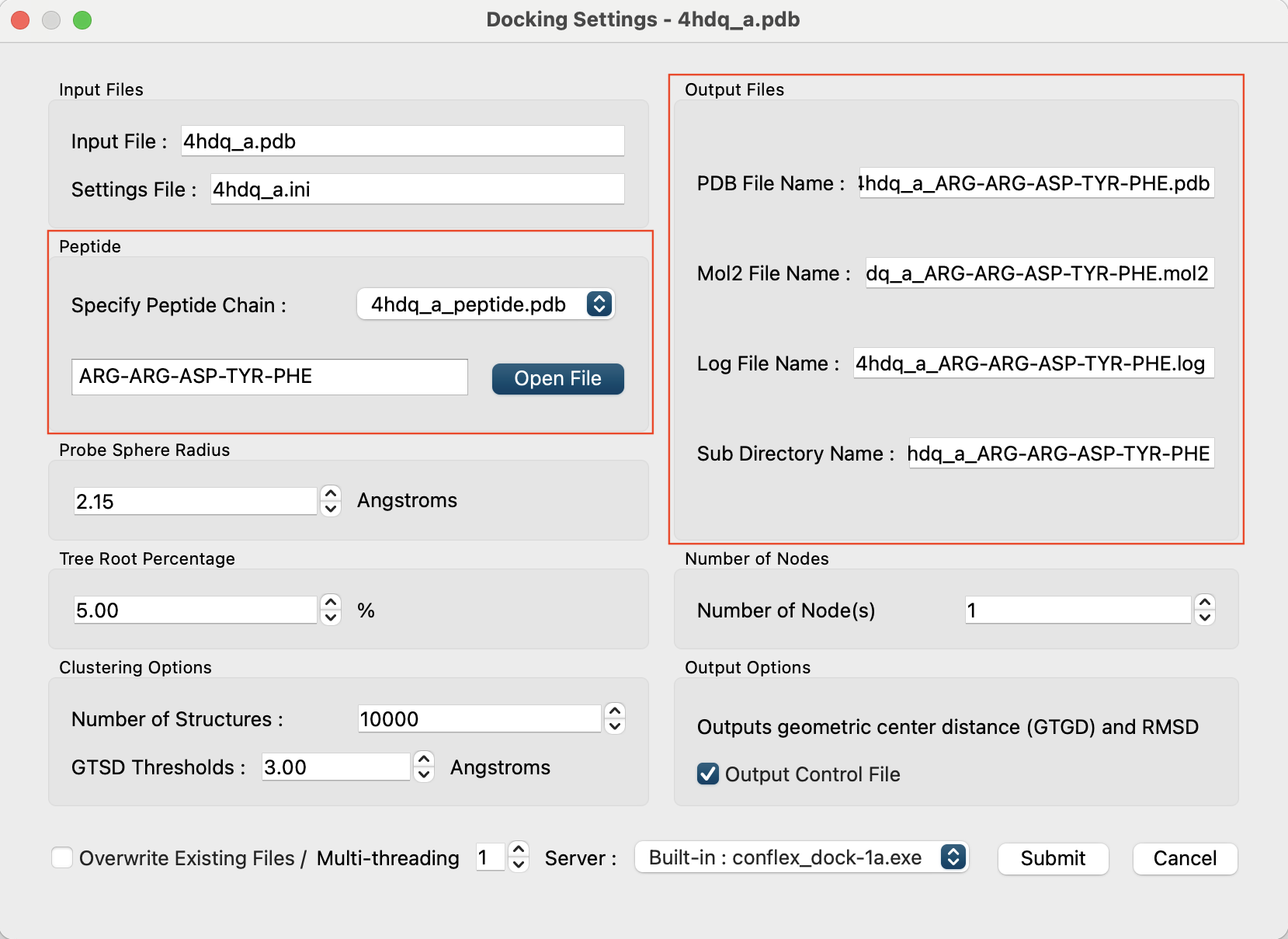
ダイアログ右下の「Submit」をクリックして、計算を開始します。
以下のようにJob Managerが起動して、「Program」列には”docking”、「Job Type」列にはペプチドのアミノ酸配列、「Molecule」列にはタンパク質のPDBファイル名がそれぞれ表示されます。

「Status」列が”running”から”Finished”に変わった後、ジョブの行をダブルクリックすると、出力ファイルの一つである4hdq_a_ARG-ARG-ASP-TYR-PHE.pdbが開きます。
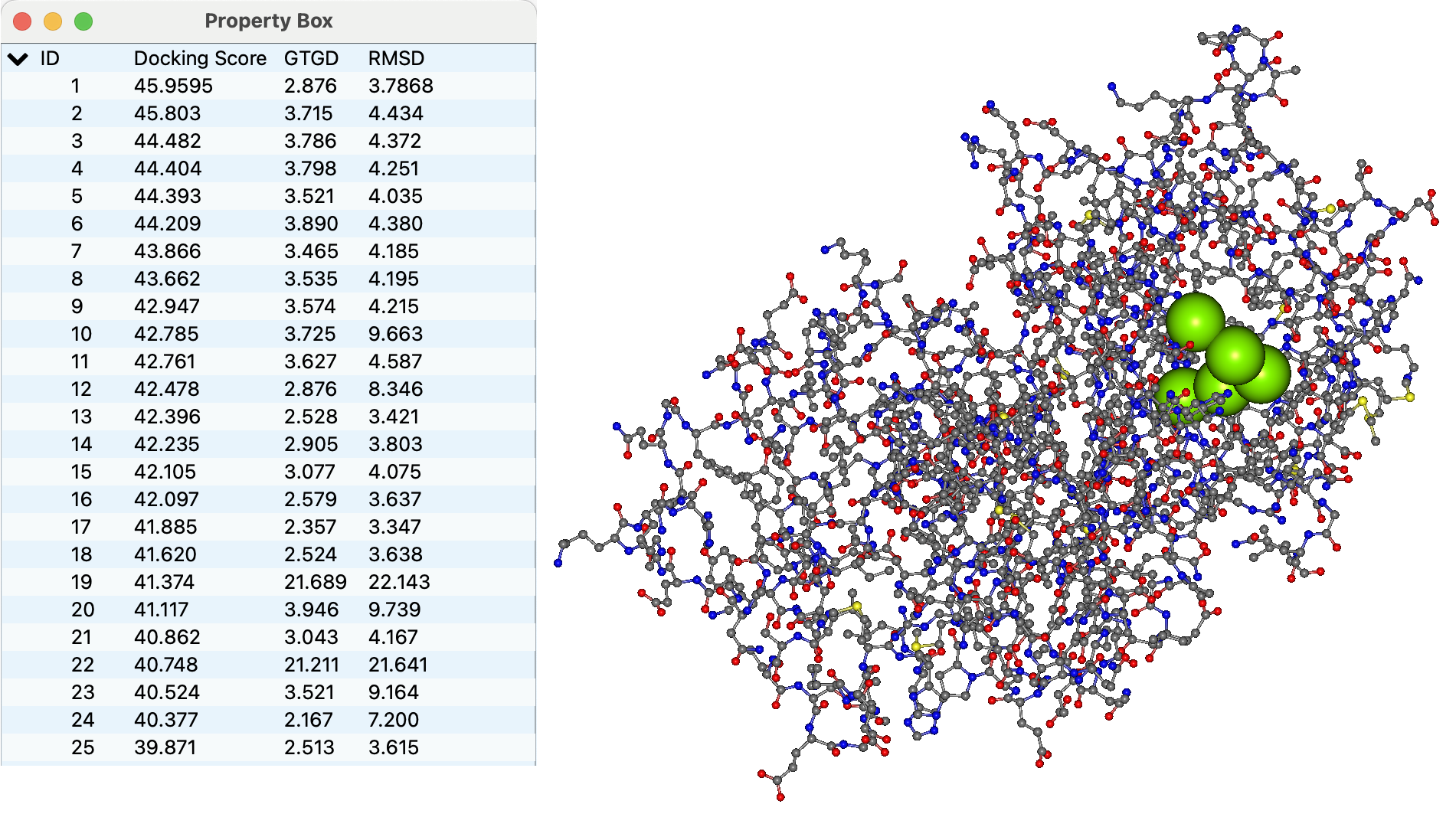
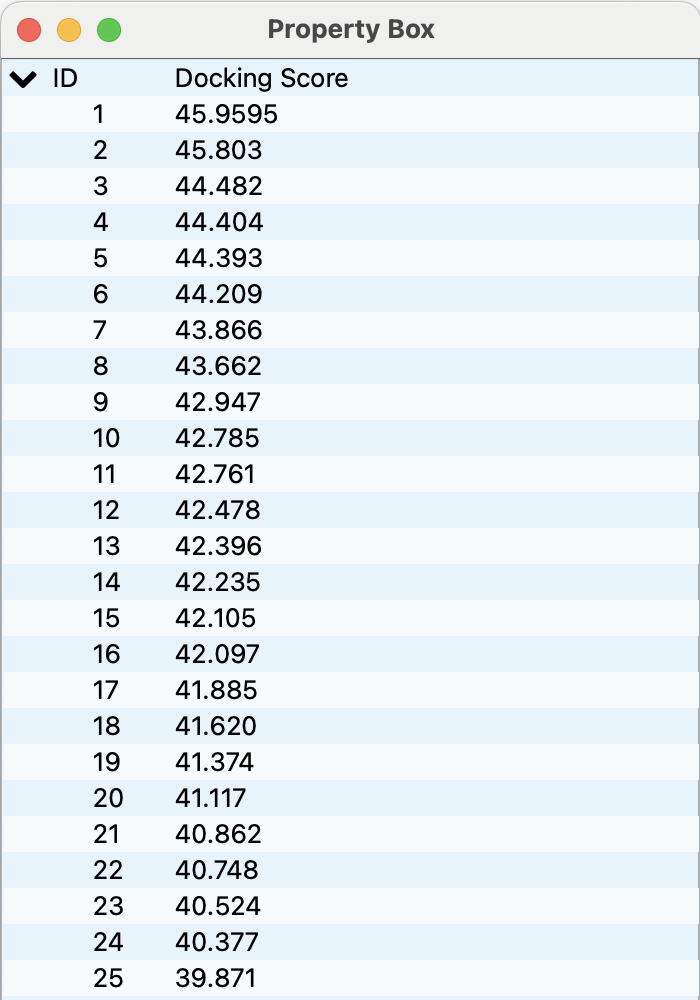
各ドッキングポーズ中での、ペプチドのアミノ酸残基の代表点が、連結した緑色の球で表されます。
またProperty Boxには、それぞれのポーズのDocking Scoreと、入力構造座標とのGeometric center To Geometric center Distance (GTGD, Å)およびRoot Mean Squared Deviation (RMSD, Å)がそれぞれ表示されます。
Property Boxで、各ID行をクリックすると表示されるドッキングポーズが切り替わります。
[出力ファイルの構成と内容]
計算が終了すると、入力ファイル4hdq_a.pdbと同じディレクトリー内に、設定内容を反映した「4hdq_a.ini」と、3つの出力ファイル
- 4hdq_a_ARG-ARG-ASP-TYR-PHE.log
- 4hdq_a_ARG-ARG-ASP-TYR-PHE.mol2
- 4hdq_a_ARG-ARG-ASP-TYR-PHE.pdb
さらに、4hdq_a_ARG-ARG-ASP-TYR-PHEというディレクトリーが作成され、ファイルが保存されています。
4hdq_a.iniは、以下の内容で保存されています。
probe_rad=2.15 root=0.05 branch=1 cluster=10000 cluster_dist=3
4hdq_a_ARG-ARG-ASP-TYR-PHE.logには、計算の経過や、各ドッキングポーズのスコア値、分布、クラスタリング結果等が出力されています。
==================================================================================================================================
_/_/_/_/ _/_/_/_/ _/ _/ _/_/_/_/ _/ _/_/_/_/ _/_/ _/_/ _/_/_/ _/_/_/_/ _/_/_/_/ _/ _/_/
_/ _/ _/ _/_/ _/ _/ _/ _/ _/ _/ _/ _/ _/ _/ _/ _/ _/
_/ _/ _/ _/ _/ _/ _/_/_/_/ _/ _/_/_/_/ _/ _/ _/ _/ _/ _/ _/_/
_/ _/ _/ _/ _/_/ _/ _/ _/ _/ _/ _/ _/ _/ _/ _/ _/ _/
_/_/_/_/ _/_/_/_/ _/ _/ _/ _/_/_/_/ _/_/_/_/ _/_/ _/_/ _/_/_/_/ _/_/_/_/ _/_/_/_/ _/ _/_/
Start --- CONFLEX DOCK ver.1.A.0303 (Updated March, 3rd, 2025)
Date: 2025/04/15
Time: 00:23:29
==================================================================================================================================
<< Licensee information >>
Licensee name: CONFLEX DOCK User
Licensing institution: CONFLEX Corporation
Address: Shinagawa Center Bldg. 6F, 3-23-17 Takanawa
City: Minato-ku, Tokyo
ZIP code: 108-0074
Nation: Japan
Telephone number: +81-3-6380-8290
E-mail address: info@conflex.co.jp
Matched MAC address: 11:22:33:44:55:66
DATE OF THE LICENSE START: 2025/04/14
DATE OF THE LICENSE EXPIRE: 2026/12/31
==================================================================================================================================
Maximum number of threads: 8
Current number of threads: 1
Directory containing Potential and License files: /Applications/CONFLEX/par
Representative point of residue: C_alpha atom
==================================================================================================================================
*** Delaunary tessellation of protein and setting of search points
Probe radius (Angstrom): 2.150
Protein file name: 4hdq_a.pdb
Number of amino acid residues in the protein: 311
Peptide file name: 4hdq_a_peptide.pdb
Number of amino acid residues in the peptide: 5
Score of peptide on the nearest search points: 30.867
GTGD of peptide on the nearest search points from input structure (Angstrom): 0.653
RMSD of peptide on the nearest search points from input structure (Angstrom): 1.562
CPU time (s): 0.734
Wall time (s): 0.734
==================================================================================================================================
「4hdq_a_ARG-ARG-ASP-TYR-PHE.mol2」には、タンパク質のアミノ酸残基も代表点として表した各ドッキングポーズが出力されています。
4hdq_a_ARG-ARG-ASP-TYR-PHEディレクトリーには、以下の10個のファイルが出力されています。
4hdq_a_4hdq_a_peptide_ClustPep_N1_DIST3.csv 4hdq_a_4hdq_a_peptide_FRank_N1_0.csv 4hdq_a_4hdq_a_peptide_ClustSite_N1_DIST3.csv 4hdq_a_4hdq_a_peptide_GRank_N1_0.csv 4hdq_a_4hdq_a_peptide_Clust_N1_DIST3.mol2 4hdq_a_4hdq_a_peptide_N1_ALL.csv 4hdq_a_4hdq_a_peptide_Clust_N1_DIST3.pdb 4hdq_a_4hdq_a_peptide_RRank_N1_0.csv 4hdq_a_4hdq_a_peptide_Distribution_N1.csv searchpoint.mol2
このうち、.csvファイルの出力内容は以下の通りです。
| ファイル名 | 説明 |
|---|---|
| 4hdq_a_4hdq_a_peptide_ClustPep_N1_DIST3.csv | クラスタリング番号(CNo)、スコア順位(FRank)、スコア(FSum)、計算順(RNo)、行番号(LNo)、GTGD、RMSD |
| 4hdq_a_4hdq_a_peptide_ClustSite_N1_DIST3.csv | クラスタリング番号(CNo)、各クラスターのポーズ数(Nc)、スコア平均(重み付け(FAve(weighted))、重み付け無し(FAve(noweighted)))、スコアの分散(重み付け無し平均(FVar))、スコアの最大値(FMax)、スコアの最小値(FMin) |
| 4hdq_a_4hdq_a_peptide_Distribution_N1.csv | スコアの分布 |
| 4hdq_a_4hdq_a_peptide_FRank_N1.csv | スコア順位(FRank)、スコア(FSum)、GTGD順位(GRank)、GTGD、RMSD順位(RRank)、RMSD、計算順(RNo)、行番号(LNo) |
| 4hdq_a_4hdq_a_peptide_GRank_N1.csv | GTGD順位(GRank)、GTGD、RMSD順位(RRank)、RMSD、スコア順位(FRank)、スコア(FSum)、計算順(RNo)、行番号(LNo) |
| 4hdq_a_4hdq_a_peptide_N1_ALL.csv | 計算順(RNo)、行番号(LNo)、各残基の配置点、スコア(FSum) |
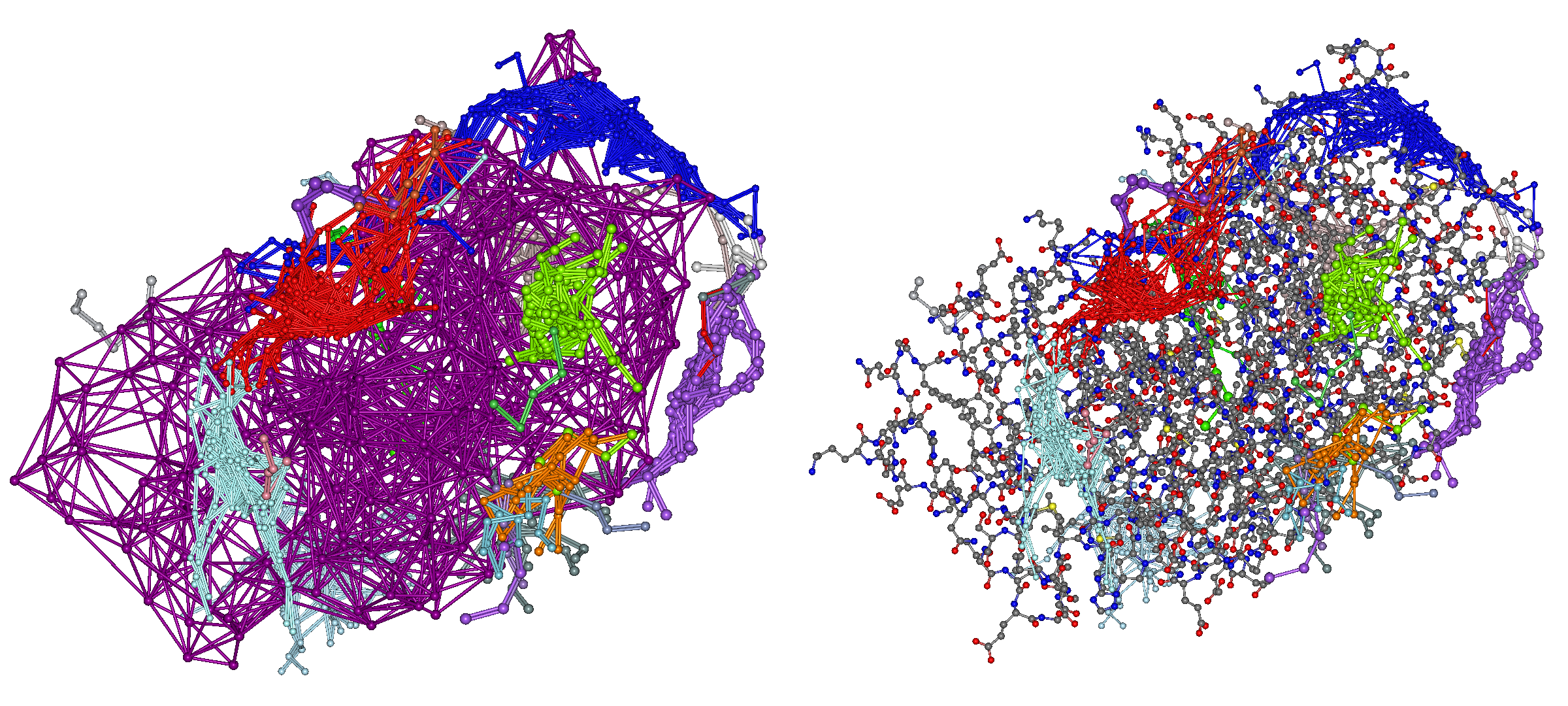
4hdq_a_4hdq_a_peptide_Clust_N1_DIST3.mol2(左)および4hdq_a_4hdq_a_peptide_Clust_N1_DIST3.pdb(右)には、全てのドッキングポーズがクラスタリングされた形で出力されており、以下のように表示されます。
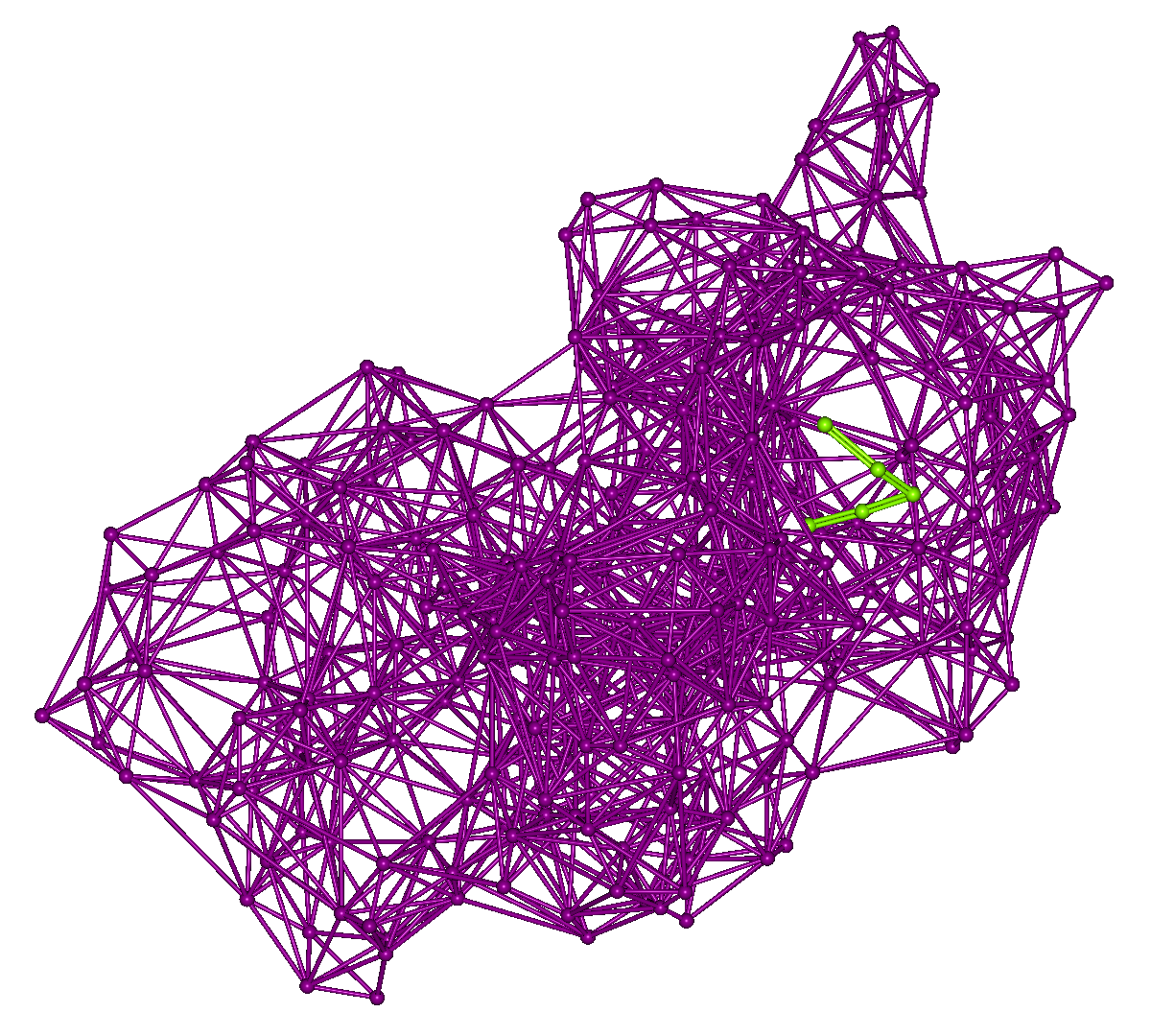
「search.mol2」には、タンパク質のアミノ酸残基の代表点と、その表面に配置したペプチドの探索点が出力されています。

[※ペプチドのアミノ酸残基配列を直接指定する場合]
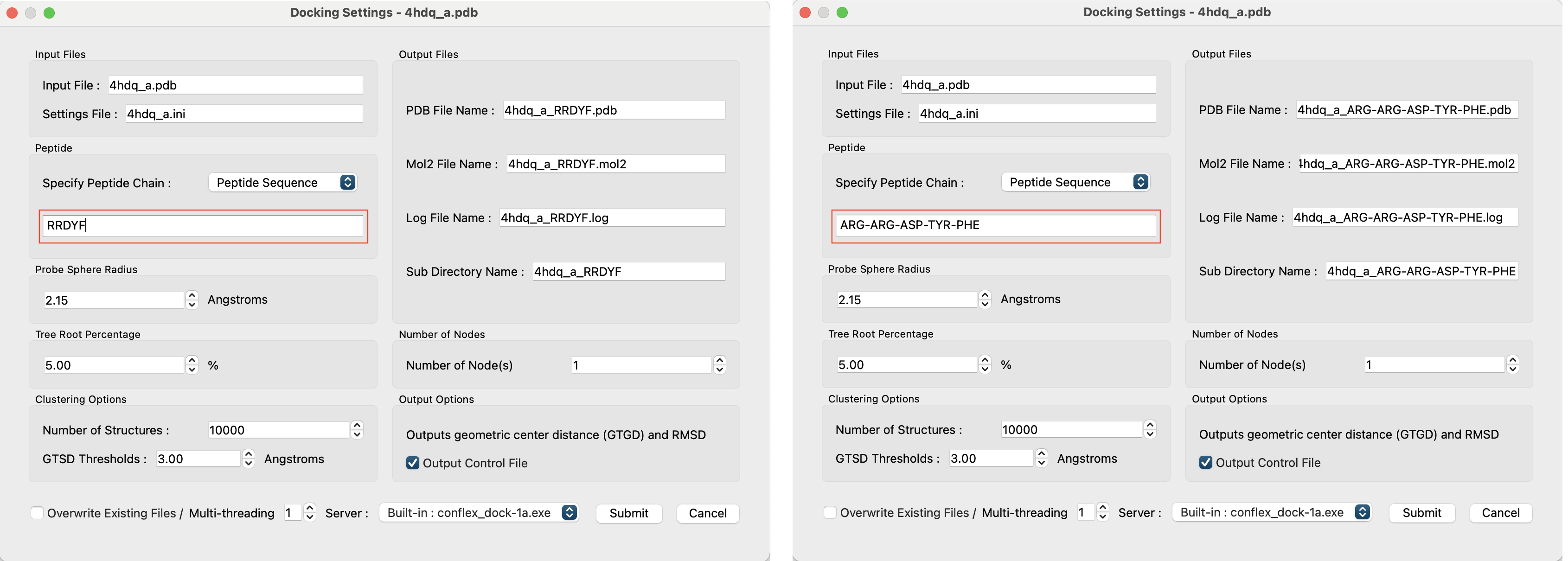
Docking Settings画面のPeptide欄に、探索するペプチドのアミノ酸残基の配列を直接入力して計算することも可能です。
配列が同じであれば、PDBファイルを設定する場合とドッキングスコアの結果は変わりません。
配列の指定は、1文字表記(左)と3文字表記(右)いずれも可能です。但し、3文字表記で入力する場合は、残基の間に”-”(ハイフン)を入れてください。
但し、参照する構造データが無いので、以下のようにGTGDおよびRMSDは出力されません。